A variant of the yield statement that can result in more concise code.

|
Just because I don't care doesn't mean I don't understand.
|

I don't use generators enough, but this is a cool tip.
Durham, NC


The logo image was taken from Reddit.
It is a living document, last update: November 2024. Your contributions are welcome!
There are so many buzzwords and best practices out there, but let's focus on something more fundamental. What matters is the amount of confusion developers feel when going through the code.
Confusion costs time and money. Confusion is caused by high cognitive load. It's not some fancy abstract concept, but rather a fundamental human constraint.
Since we spend far more time reading and understanding code than writing it, we should constantly ask ourselves whether we are embedding excessive cognitive load into our code.
Cognitive load is how much a developer needs to think in order to complete a task.
When reading code, you put things like values of variables, control flow logic and call sequences into your head. The average person can hold roughly four such chunks in working memory. Once the cognitive load reaches this threshold, it becomes much harder to understand things.
Let's say we have been asked to make some fixes to a completely unfamiliar project. We were told that a really smart developer had contributed to it. Lots of cool architectures, fancy libraries and trendy technologies were used. In other words, the author had created a high cognitive load for us.

We should reduce the cognitive load in our projects as much as possible.
Intrinsic - caused by the inherent difficulty of a task. It can't be reduced, it's at the very heart of software development.
Extraneous - created by the way the information is presented. Caused by factors not directly relevant to the task, such as smart author's quirks. Can be greatly reduced. We will focus on this type of cognitive load.

Let's jump straight to the concrete practical examples of extraneous cognitive load.
We will refer to the level cognitive load as follows:🧠: fresh working memory, zero cognitive load🧠++: two facts in our working memory, cognitive load increased🤯: cognitive overload, more than 4 facts
Our brain is much more complex and unexplored, but we can go with this simplistic model.
if val > someConstant
&& (condition2 || condition3)
&& (condition4 && !condition5) {
...
}
Introduce intermediate variables with meaningful names:
isValid = val > someConstant
isAllowed = condition2 || condition3
isSecure = condition4 && !condition5
if isValid && isAllowed && isSecure {
...
}
if isValid {
if isSecure {
stuff // 🧠+++
}
}
Compare it with the early returns:
if !isValid
return
if !isSecure
return
stuff
We can focus on the happy path only, thus freeing our working memory from all sorts of preconditions.
We are asked to change a few things for our admin users: 🧠
AdminController extends UserController extends GuestController extends BaseControllerOhh, part of the functionality is in BaseController, let's have a look: 🧠+
Basic role mechanics got introduced in GuestController: 🧠++
Things got partially altered in UserController: 🧠+++
Finally we are here, AdminController, let's code stuff! 🧠++++
Oh, wait, there's SuperuserController which extends AdminController. By modifying AdminController we can break things in the inherited class, so let's dive in SuperuserController first: 🤯
Prefer composition over inheritance. We won't go into detail - there's plenty of material out there.
Method, class and module are interchangeable in this context
Mantras like "methods should be shorter than 15 lines of code" or "classes should be small" turned out to be somewhat wrong.
Deep module - simple interface, complex functionality
Shallow module - interface is relatively complex to the small functionality it provides

Having too many shallow modules can make it difficult to understand the project. Not only do we have to keep in mind each module responsibilities, but also all their interactions. To understand the purpose of a shallow module, we first need to look at the functionality of all the related modules. 🤯
Information hiding is paramount, and we don't hide as much complexity in shallow modules.
I have two pet projects, both of them are somewhat 5K lines of code. The first one has 80 shallow classes, whereas the second one has only 7 deep classes. I haven't been maintaining any of these projects for one year and a half.
Once I came back, I realised that it was extremely difficult to untangle all the interactions between those 80 classes in the first project. I would have to rebuild an enormous amount of cognitive load before I could start coding. On the other hand, I was able to grasp the second project quickly, because it had only a few deep classes with a simple interface.
The best components are those that provide powerful functionality yet have simple interface.
John K. Ousterhout
The interface of the UNIX I/O is very simple. It has only five basic calls:
open(path, flags, permissions)
read(fd, buffer, count)
write(fd, buffer, count)
lseek(fd, offset, referencePosition)
close(fd)
A modern implementation of this interface has hundreds of thousands of lines of code. Lots of complexity is hidden under the hood. Yet it is easy to use due to its simple interface.
This deep module example is taken from the book A Philosophy of Software Design by John K. Ousterhout. Not only does this book cover the very essence of complexity in software development, but it also has the greatest interpretation of Parnas' influential paper On the Criteria To Be Used in Decomposing Systems into Modules. Both are essential reads. Other related readings: It's probably time to stop recommending Clean Code, Small Functions considered Harmful.
P.S. If you think we are rooting for bloated God objects with too many responsibilities, you got it wrong.
All too often, we end up creating lots of shallow modules, following some vague "a module should be responsible for one, and only one, thing" principle. What is this blurry one thing? Instantiating an object is one thing, right? So MetricsProviderFactoryFactory seems to be just fine. The names and interfaces of such classes tend to be more mentally taxing than their entire implementations, what kind of abstraction is that? Something went wrong.
Jumping between such shallow components is mentally exhausting, linear thinking is more natural to us humans.
We make changes to our systems to satisfy our users and stakeholders. We are responsible to them.
A module should be responsible to one, and only one, user or stakeholder.
This is what this Single Responsibility Principle is all about. Simply put, if we introduce a bug in one place, and then two different business people come to complain, we've violated the principle. It has nothing to do with the number of things we do in our module.
But even now, this interpretation can do more harm than good. This rule can be understood in as many different ways as there are individuals. A better approach would be to look at how much cognitive load it all creates. It's mentally demanding to remember that change in one module can trigger a chain of reactions across different business streams. And that's about it.
This shallow-deep module principle is scale-agnostic, and we can apply it to microservices architecture. Too many shallow microservices won't do any good - the industry is heading towards somewhat "macroservices", i.e., services that are not so shallow (=deep). One of the worst and hardest to fix phenomena is so-called distributed monolith, which is often the result of this overly granular shallow separation.
I once consulted a startup where a team of five developers introduced 17(!) microservices. They were 10 months behind schedule and appeared nowhere close to the public release. Every new requirement led to changes in 4+ microservices. Diagnostic difficulty in integration space skyrocketed. Both time to market and cognitive load were unacceptably high. 🤯
Is this the right way to approach the uncertainty of a new system? It's enormously difficult to elicit the right logical boundaries in the beginning. The key is to make decisions as late as you can responsibly wait, because that is when you have the most information on which to base the decision. By introducing a network layer up front, we make our design decisions hard to revert right from the start. The team's only justification was: "The FAANG companies proved microservices architecture to be effective". Hello, you got to stop dreaming big.
The Tanenbaum-Torvalds debate argued that Linux's monolithic design was flawed and obsolete, and that a microkernel architecture should be used instead. Indeed, the microkernel design seemed to be superior "from a theoretical and aesthetical" point of view. On the practical side of things - three decades on, microkernel-based GNU Hurd is still in development, and monolithic Linux is everywhere. This page is powered by Linux, your smart teapot is powered by Linux. By monolithic Linux.
A well-crafted monolith with truly isolated modules is often much more flexible than a bunch of microservices. It also requires far less cognitive effort to maintain. It's only when the need for separate deployments becomes crucial, such as scaling the development team, that you should consider adding a network layer between the modules, future microservices.
We feel excited when new features got released in our favourite language. We spend some time learning these features, we build code upon them.
If there are lots of features, we may spend half an hour playing with a few lines of code, to use one or another feature. And it's kind of a waste of time. But what's worse, when you come back later, you would have to recreate that thought process!
You not only have to understand this complicated program, you have to understand why a programmer decided this was the way to approach a problem from the features that are available. 🤯
These statements are made by none other than Rob Pike.
Reduce cognitive load by limiting the number of choices.
Language features are OK, as long as they are orthogonal to each other.
Thoughts from an engineer with 20 years of C++ experience ⭐️
On the backend we return:
I was looking at my RSS reader the other day and noticed that I have somewhat three hundred unread articles under the "C++" tag. I haven't read a single article about the language since last summer, and I feel great!
I've been using C++ for 20 years for now, that's almost two-thirds of my life. Most of my experience lies in dealing with the darkest corners of the language (such as undefined behaviours of all sorts). It's not a reusable experience, and it's kind of creepy to throw it all away now.
Like, can you imagine, the token || has a different meaning in requires ((!P<T> || !Q<T>)) and in requires (!(P<T> || Q<T>)). The first is the constraint disjunction, the second is the good-old logical or operator, and they behave differently.
You can't allocate space for a trivial type and just memcpy a set of bytes there without extra effort - that won't start the lifetime of an object. This was the case before C++20. It was fixed in C++20, but the cognitive load of the language has only increased.
Cognitive load is constantly growing, even though things got fixed. I should know what was fixed, when it was fixed, and what it was like before. I am a professional after all. Sure, C++ is good at legacy support, which also means that you will face that legacy. For example, last month a colleague of mine asked me about some behaviour in C++03. 🤯
There were 20 ways of initialization. Uniform initialization syntax has been added. Now we have 21 ways of initialization. By the way, does anyone remember the rules for selecting constructors from the initializer list? Something about implicit conversion with the least loss of information, but if the value is known statically, then... 🤯
This increased cognitive load is not caused by a business task at hand. It is not an intrinsic complexity of the domain. It is just there due to historical reasons (extraneous cognitive load).
I had to come up with some rules. Like, if that line of code is not as obvious and I have to remember the standard, I better not write it that way. The standard is somewhat 1500 pages long, by the way.
By no means I am trying to blame C++. I love the language. It's just that I am tired now.
401for expired jwt token403for not enough access418for banned users
The guys on the frontend use backend API to implement login functionality. They would have to temporarily create the following cognitive load in their brains:
401is for expired jwt token //🧠+, ok just temporary remember it403is for not enough access //🧠++418is for banned users //🧠+++
Frontend developers would (hopefully) introduce some kind numeric status -> meaning dictionary on their side, so that subsequent generations of contributors wouldn't have to recreate this mapping in their brains.
Then QA people come into play:
"Hey, I got 403 status, is that expired token or not enough access?"
QA people can't jump straight to testing, because first they have to recreate the cognitive load that the guys on the backend once created.
Why hold this custom mapping in our working memory? It's better to abstract away your business details from the HTTP transfer protocol, and return self-descriptive codes directly in the response body:
{
"code": "jwt_has_expired"
}
Cognitive load on the frontend side: 🧠 (fresh, no facts are held in mind)
Cognitive load on the QA side: 🧠
The same rule applies to all sorts of numeric statuses (in the database or wherever) - prefer self-describing strings. We are not in the era of 640K computers to optimise for memory.
People spend time arguing between
401and403, making decisions based on their own mental models. New developers are coming in, and they need to recreate that thought process. You may have documented the "whys" (ADRs) for your code, helping newcomers to understand the decisions made. But in the end it just doesn't make any sense. We can separate errors into either user-related or server-related, but apart from that, things are kind of blurry.
P.S. It's often mentally taxing to distinguish between "authentication" and "authorization". We can use simpler terms like "login" and "permissions" to reduce the cognitive load.
Do not repeat yourself - that is one of the first principles you are taught as a software engineer. It is so deeply embedded in ourselves that we can not stand the fact of a few extra lines of code. Although in general a good and fundamental rule, when overused it leads to the cognitive load we can not handle.
Nowadays, everyone builds software based on logically separated components. Often those are distributed among multiple codebases representing separate services. When you strive to eliminate any repetition, you might end up creating tight coupling between unrelated components. As a result changes in one part may have unintended consequences in other seemingly unrelated areas. It can also hinder the ability to replace or modify individual components without impacting the entire system. 🤯
In fact, the same problem arises even within a single module. You might extract common functionality too early, based on perceived similarities that might not actually exist in the long run. This can result in unnecessary abstractions that are difficult to modify or extend.
Rob Pike once said:
A little copying is better than a little dependency.
We are tempted to not reinvent the wheel so strong that we are ready to import large, heavy libraries to use a small function that we could easily write by ourselves.
All your dependencies are your code. Going through 10+ levels of stack trace of some imported library and figuring out what went wrong (because things go wrong) is painful.
There's a lot of "magic" in frameworks. By relying too heavily on a framework, we force all upcoming developers to learn that "magic" first. It can take months. Even though frameworks enable us to launch MVPs in a matter of days, in the long run they tend to add unnecessary complexity and cognitive load.
Worse yet, at some point frameworks can become a significant constraint when faced with a new requirement that just doesn't fit the architecture. From here onwards people end up forking a framework and maintaining their own custom version. Imagine the amount of cognitive load a newcomer would have to build (i.e. learn this custom framework) in order to deliver any value. 🤯
By no means do we advocate to invent everything from scratch!
We can write code in a somewhat framework-agnostic way. The business logic should not reside within a framework; rather, it should use the framework's components. Put a framework outside of your core logic. Use the framework in a library-like fashion. This would allow new contributors to add value from day one, without the need of going through debris of framework-related complexity first.
Why I Hate Frameworks
There is a certain engineering excitement about all this stuff.
I myself was a passionate advocate of Hexagonal/Onion Architecture for years. I used it here and there and encouraged other teams to do so. The complexity of our projects went up, the sheer number of files alone had doubled. It felt like we were writing a lot of glue code. On ever changing requirements we had to make changes across multiple layers of abstractions, it all became tedious. 🤯
Abstraction is supposed to hide complexity, here it just adds indirection. Jumping from call to call to read along and figure out what goes wrong and what is missing is a vital requirement to quickly solve a problem. With this architecture’s layer uncoupling it requires an exponential factor of extra, often disjointed, traces to get to the point where the failure occurs. Every such trace takes space in our limited working memory. 🤯
This architecture was something that made intuitive sense at first, but every time we tried applying it to projects it made a lot more harm than good. In the end, we gave it all up in favour of the good old dependency inversion principle. No port/adapter terms to learn, no unnecessary layers of horizontal abstractions, no extraneous cognitive load.
If you think that such layering will allow you to quickly replace a database or other dependencies, you're mistaken. Changing the storage causes lots of problems, and believe us, having some abstractions for the data access layer is the least of your worries. At best, abstractions can save somewhat 10% of your migration time (if any), the real pain is in data model incompatibilities, communication protocols, distributed systems challenges, and implicit interfaces.
With a sufficient number of users of an API,
it does not matter what you promise in the contract:
all observable behaviors of your system
will be depended on by somebody.
The law of implicit interfaces
We did a storage migration, and that took us about 10 months. The old system was single-threaded, so the exposed events were sequential. All our systems depended on that observed behaviour. This behavior was not part of the API contract, it was not reflected in the code. A new distributed storage didn't have that guarantee - the events came out-of-order. We spent only a few hours coding a new storage adapter. We spent the next 10 months on dealing with out-of-order events and other challenges. It's now funny to say that layering helps us replace components quickly.
So, why pay the price of high cognitive load for such a layered architecture, if it doesn't pay off in the future? Plus, in most cases, that future of replacing some core component never happens.
These architectures are not fundamental, they are just subjective, biased consequences of more fundamental principles. Why rely on those subjective interpretations? Follow the fundamental rules instead: dependency inversion principle, cognitive load and information hiding. Discuss.
Do not add layers of abstractions for the sake of an architecture. Add them whenever you need an extension point that is justified for practical reasons. Layers of abstraction aren't free of charge, they are to be held in our working memory.
Domain-driven design has some great points, although it is often misinterpreted. People say "We write code in DDD", which is a bit strange, because DDD is about problem space, not about solution space.
Ubiquitous language, domain, bounded context, aggregate, event storming are all about problem space. They are meant to help us learn the insights about the domain and extract the boundaries. DDD enables developers, domain experts and business people to communicate effectively using a single, unified language. Rather than focusing on these problem space aspects of DDD, we tend to emphasise particular folder structures, services, repositories, and other solution space techniques.
Chances are that the way we interpret DDD is likely to be unique and subjective. And if we build code upon this understanding, i.e., if we create a lot of extraneous cognitive load - future developers are doomed. 🤯
These architectures are quite boring and easy to understand. Anyone can grasp them without much mental effort.
Involve junior developers in architecture reviews. They will help you to identify the mentally demanding areas.
The problem is that familiarity is not the same as simplicity. They feel the same — that same ease of moving through a space without much mental effort — but for very different reasons. Every “clever” (read: “self-indulgent”) and non-idiomatic trick you use incurs a learning penalty for everyone else. Once they have done that learning, then they will find working with the code less difficult. So it is hard to recognise how to simplify code that you are already familiar with. This is why I try to get “the new kid” to critique the code before they get too institutionalised!
It is likely that the previous author(s) created this huge mess one tiny increment at a time, not all at once. So you are the first person who has ever had to try to make sense of it all at once.
In my class I describe a sprawling SQL stored procedure we were looking at one day, with hundreds of lines of conditionals in a huge WHERE clause. Someone asked how anyone could have let it get this bad. I told them: “When there are only 2 or 3 conditionals, adding another one doesn’t make any difference. By the time there are 20 or 30 conditionals, adding another one doesn’t make any difference!”
There is no “simplifying force” acting on the code base other than deliberate choices that you make. Simplifying takes effort, and people are too often in a hurry.
Thanks to Dan North for his comment.
If you've internalized the mental models of the project into your long-term memory, you won't experience a high cognitive load.

The more mental models there are to learn, the longer it takes for a new developer to deliver value.
Once you onboard new people on your project, try to measure the amount of confusion they have (pair programming may help). If they're confused for more than ~40 minutes in a row - you've got things to improve in your code.
If you keep the cognitive load low, people can contribute to your codebase within the first few hours of joining your company.
Imagine for a moment that what we inferred in the second chapter isn’t actually true. If that’s the case, then the conclusion we just negated, along with the conclusions in the previous chapter that we had accepted as valid, might not be correct either. 🤯
Do you feel it? Not only do you have to jump all over the article to get the meaning (shallow modules!), but the paragraph in general is difficult to understand. We have just created an unnecessary cognitive load in your head. Do not do this to your colleagues.
We should reduce any cognitive load above and beyond what is intrinsic to the work we do.
Some good ideas here.
Durham, NC
The last month has transformed the state of AI, with the pace picking up dramatically in just the last week. AI labs have unleashed a flood of new products - some revolutionary, others incremental - making it hard for anyone to keep up. Several of these changes are, I believe, genuine breakthroughs that will reshape AI's (and maybe our) future. Here is where we now stand:
Smart AIs are now everywhere
At the end of last year, there was only one publicly available GPT-4/Gen2 class model, and that was GPT-4. Now there are between six and ten such models, and some of them are open weights, which means they are free for anyone to use or modify. From the US we have OpenAI’s GPT-4o, Anthropic’s Claude Sonnet 3.5, Google’s Gemini 1.5, the open Llama 3.2 from Meta, Elon Musk’s Grok 2, and Amazon’s new Nova. Chinese companies have released three open multi-lingual models that appear to have GPT-4 class performance, notably Alibaba’s Qwen, R1’s DeepSeek, and 01.ai’s Yi. Europe has a lone entrant in the space, France’s Mistral. What this word salad of confusing names means is that building capable AIs did not involve some magical formula only OpenAI had, but was available to companies with computer science talent and the ability to get the chips and power needed to train a model.
In fact, GPT-4 level artificial intelligence, so startling when it was released that it led to considerable anxiety about the future, can now be run on my home computer. Meta’s newest small model, released this month, named Llama 3.3, offers similar performance and can operate entirely offline on my gaming PC. And the new, tiny Phi 4 from Microsoft is GPT-4 level and can almost run on your phone, while its slightly less capable predecessor, Phi 3.5, certainly can. Intelligence, of a sort, is available on demand.
And, as I have discussed (and will post about again soon), these ubiquitous AIs are now starting to power agents, autonomous AIs that can pursue their own goals. You can see what that means in this post, where I use early agents to do comparison shopping and monitor a construction site.
VERY smart AIs are now here
All of this means that if GPT-4 level performance was the maximum an AI could achieve, that would likely be enough for us to have five to ten years of continued change as we got used to their capabilities. But there isn’t a sign that a major slowdown in AI development is imminent. We know this because the last month has had two other significant releases - the first sign of the Gen3 models (you can think of these as GPT-5 class models) and the release of the o1 models that can “think” before answering, effectively making them much better reasoners than other LLMs. We are in the early days of Gen3 releases, so I am not going to write about them too much in this post, but I do want to talk about o1.
I discussed the o1 release when it came out in early o1-preview form, but two more sophisticated variants, o1 and o1-pro, have considerably increased power. These models spend time invisibly “thinking” - mimicking human logical problem solving - before answering questions. This approach, called test time compute, turns out to be a key to making models better at problem solving. In fact, these models are now smart enough to make meaningful contributions to research, in ways big and small.
As one fun example, I read an article about a recent social media panic - an academic paper suggested that black plastic utensils could poison you because they were partially made with recycled e-waste. A compound called BDE-209 could leach from these utensils at such a high rate, the paper suggested, that it would approach the safe levels of dosage established by the EPA. A lot of people threw away their spatulas, but McGill University’s Joe Schwarcz thought this didn’t make sense and identified a math error where the authors incorrectly multiplied the dosage of BDE-209 by a factor of 10 on the seventh page of the article - an error missed by the paper’s authors and peer reviewers. I was curious if o1 could spot this error. So, from my phone, I pasted in the text of the PDF and typed: “carefully check the math in this paper.” That was it. o1 spotted the error immediately (other AI models did not).

When models are capable enough to not just process an entire academic paper, but to understand the context in which “checking math” makes sense, and then actually check the results successfully, that radically changes what AIs can do. In fact, my experiment, along with others doing the same thing, helped inspire an effort to see how often o1 can find errors in the scientific literature. We don’t know how frequently o1 can pull off this sort of feat, but it seems important to find out, as it points to a new frontier of capabilities.
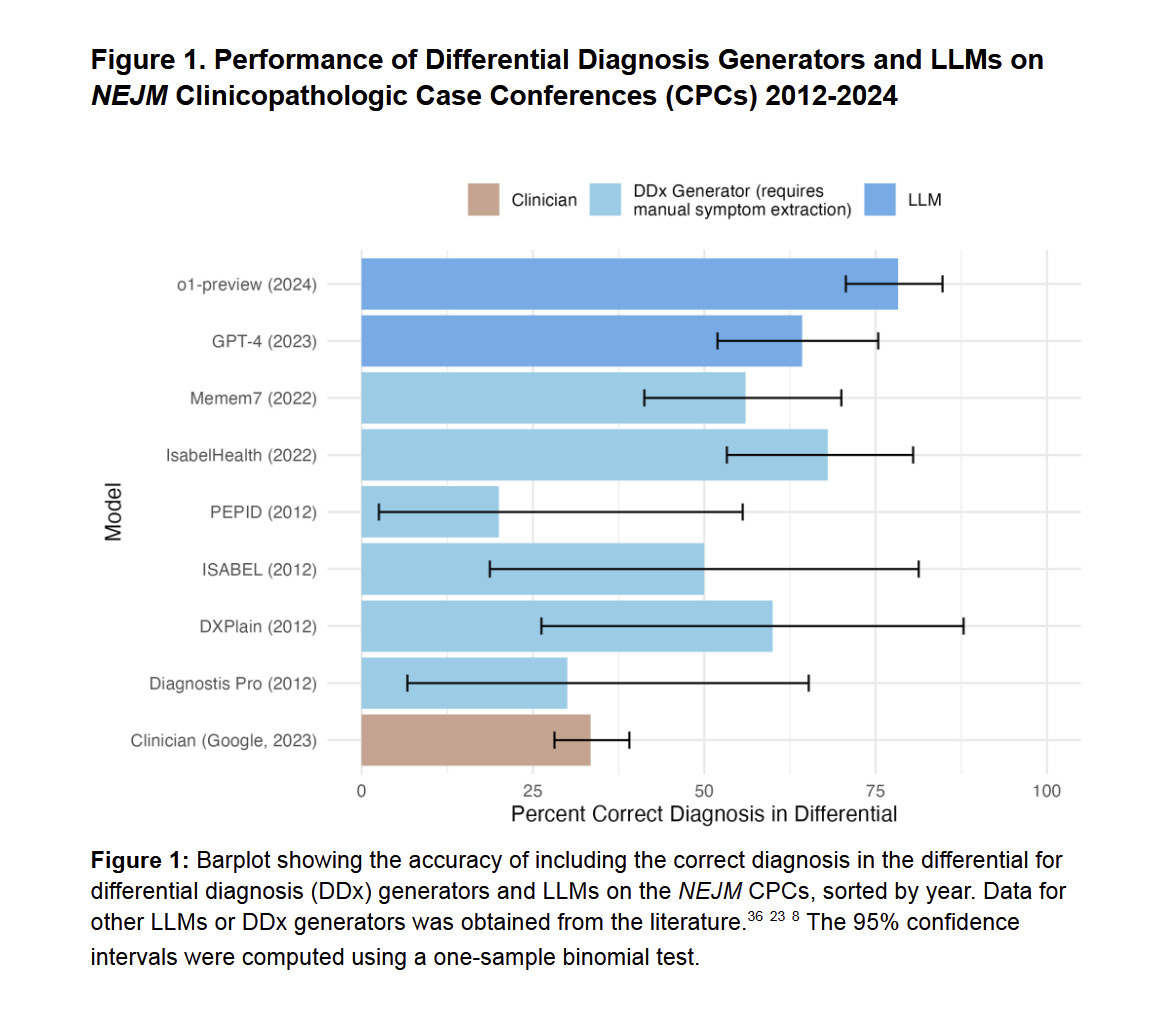
In fact, even the earlier version of o1, the preview model, seems to represent a leap in scientific ability. A bombshell of a medical working paper from Harvard, Stanford, and other researchers concluded that “o1-preview demonstrates superhuman performance [emphasis mine] in differential diagnosis, diagnostic clinical reasoning, and management reasoning, superior in multiple domains compared to prior model generations and human physicians." The paper has not been through peer review yet, and it does not suggest that AI can replace doctors, but it, along with the results above, does suggest a changing world where not using AI as a second opinion may soon be a mistake.
Potentially more significantly, I have increasingly been told by researchers that o1, and especially o1-pro, is generating novel ideas and solving unexpected problems in their field (here is one case). The issue is that only experts can now evaluate whether the AI is wrong or right. As an example, my very smart colleague at Wharton, Daniel Rock, asked me to give o1-pro a challenge: “ask it to prove, using a proof that isn’t in the literature, the universal function approximation theorem for neural networks without 1) assuming infinitely wide layers and 2) for more than 2 layers.” Here is what it wrote back:

Is this right? I have no idea. This is beyond my fields of expertise. Daniel and other experts who looked at it couldn’t tell whether it was right at first glance, either, but felt it was interesting enough to look into. It turns out the proof has errors (though it might be that more interactions with o1-pro could fix them). But the results still introduced some novel approaches that spurred further thinking. As Daniel noted to me, when used by researchers, o1 doesn’t need to be right to be useful: “Asking o1 to complete proofs in creative ways is effectively asking it to be a research colleague. The model doesn't have to get proofs right to be useful, it just has to help us be better researchers.”
We now have an AI that seems to be able to address very hard, PhD-level problems, or at least work productively as a co-intelligence for researchers trying to solve them. Of course, the issue is that you don’t actually know if these answers are right unless you are a PhD in a field yourself, creating a new set of challenges in AI evaluation. Further testing will be needed to understand how useful it is, and in what fields, but this new frontier in AI ability is worth watching.
AIs can watch and talk to you
We have had AI voice models for a few months, but the last week saw the introduction of a new capability - vision. Both ChatGPT and Gemini can now see live video and interact with voice simultaneously. For example, I can now share a live screen with Gemini’s new small Gen3 model, Gemini 2.0 Flash. You should watch it give me feedback on a draft of this post to see what this feels like:
Or even better, try it yourself for free. Seriously, it is worth experiencing what this system can do. Gemini 2.0 Flash is still a small model with a limited memory, but you start to see the point here. Models that can interact with humans in real time through the most common human senses - vision and voice - turn AI into present companions, in the room with you, rather than entities trapped in a chat box on your computer. The fact that ChatGPT Advanced Voice Mode can do the same thing from your phone means this capability is widely available to millions of users. The implications are going to be quite profound as AI becomes more present in our lives.
AI video suddenly got very good
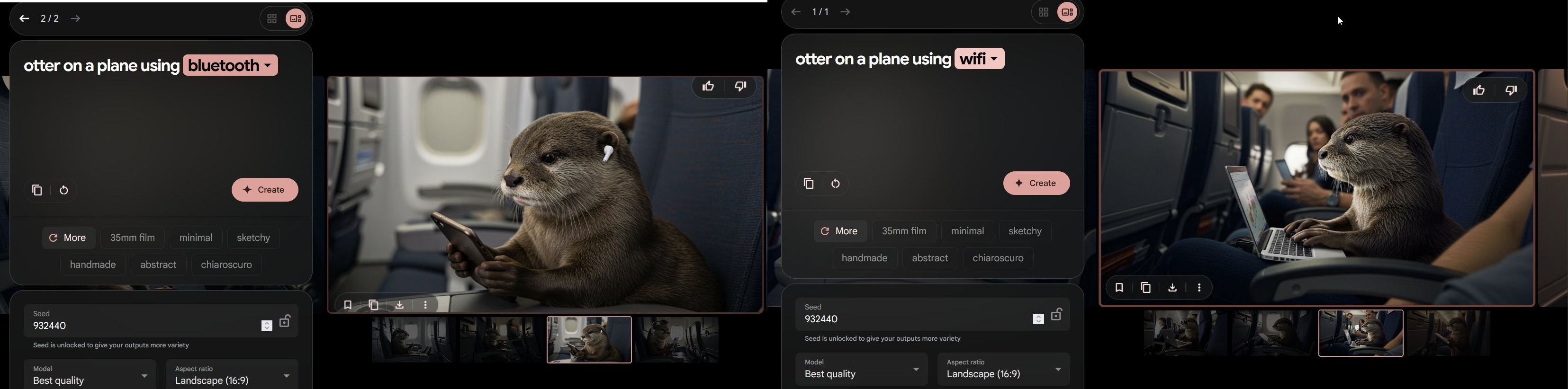
AI image creation has become really impressive over the past year, with models that can run on my laptop producing images that are indistinguishable from real photographs. They have also become much easier to direct, responding appropriately for the prompts “otter on a plane using bluetooth” and “otter on a plane using wifi.” If you want to experiment yourself, Google’s ImageFX is a really easy interface for using the powerful Imagen 3 model which was released in the last week.
But the real leap in the last week has come from AI text-to-video generators. Previously, AI models from Chinese companies generally represented the state-of-the-art in video generation, including impressive systems like Kling, as well as some open models. But the situation is changing rapidly. First, OpenAI released its powerful Sora tool and then Google, in what has become a theme of late, released its even more powerful Veo 2 video creator. You can play with Sora now if you subscribe to ChatGPT Plus, and it is worth doing, but I got early access to Veo 2 (coming in a month or two, apparently) and it is… astonishing.
It is always better to show than tell, so take a look at this compilation of 8 second clips (the limit for right now, though it can apparently do much longer movies). I provide the exact prompt in each clip, and the clips are only selected from the very first set of movies that Veo 2 made (it creates four clips at a time), so there is no cherry-picking from many examples. Pay attention to the apparent weight and heft of objects, shadows and reflection, the consistency across scenes as hair style and details are maintained, and how close the scenes are to what I asked for (the red balloon is there, if you look for it). There are errors, but they are now much harder to spot at first glance (though it still struggles with gymnastics, which are very hard for video models). Really impressive.
What does this all mean?
I will save a more detailed reflection for a future post, but the lesson to take away from this is that, for better and for worse, we are far from seeing the end of AI advancement. What's remarkable isn't just the individual breakthroughs - AIs checking math papers, generating nearly cinema-quality video clips, or running on gaming PCs. It's the pace and breadth of change. A year ago, GPT-4 felt like a glimpse of the future. Now it's basically running on phones, while new models are catching errors that slip past academic peer review. This isn't steady progress - we're watching AI take uneven leaps past our ability to easily gauge its implications. And this suggests that the opportunity to shape how these technologies transform your field exists now, when the situation is fluid, and not after the transformation is complete.

Wow!
Durham, NC
A thread of some letters people wrote to each other on clay tablets in Mesopotamia thousands of years ago. “I am the servant of my lord. May my lord not withhold a chariot from me.”
It turns out that people's conversations have always been pretty dull!
Durham, NC
This is going to be interesting.
It’s a video of someone trying on a variety of printed full-face masks. They won’t fool anyone for long, but will survive casual scrutiny. And they’re cheap and easy to swap.
Yeesh. Our race to the bottom continues.
Durham, NC
2 public comments

Holy crap!
Lexington, KY; Naples, FL

Full-Face masks look convincing for a static expression. Could effectively keep you anonymous from security and surveillance cameras. Probably not useful in defeating AI based age verification.



I'll admit to microwaving the mug and tea bag. It works well for me!
Durham, NC
7 public comments

I put my strongest small ceramic bakeware in the toaster oven, filled with water. Sometimes you just gotta do things slow and appreciate life. Not like you'll be appreciating the tea; it's still not ready yet.
East Helena, MT



You can’t microwave water, it will be polluted with radiation! Do you really want your kids exposed to electromagnetic waves?
Bend, Oregon
It's not that 110V kettles are less efficient at turning electricity to heat than 240V - they're just less powerful. UK kettles draw up to 3 kilowatts, while ones in the US max out at around half that.




What's weird is when you get into the details. Apparently American electric kettles are much slower than British ones (British people keep telling me it takes 30 seconds to boil water in an electric kettle; mine takes 5 minutes) while American microwaves are much faster (Again, takes 90 seconds in mine; they claim it takes 10 minutes). (There is some truth here; electric kettles are less efficient using American 110 mains voltage, not sure why British microwaves are so weak though)
Columbia, MD
Ah, Americans. Literally nobody "makes it in a kettle". You boil the water in a kettle and make the tea in a teapot. Obviously.

What about microwaving the crown jewels?




No, of course we don't microwave the mug WITH the teabag in it. We microwave the teabag separately.
Next Page of Stories